레디스(Redis) @sujin-kk
What is Redis?
Remote Dictionary Server : 외부에 key-value를 저장하는 서버
💡 대표적인 NoSQL, 비관계형 데이터베이스 시스템!
가장 큰 특징은,,
key-value 구조로 비정형 데이터를 저장 및 관리 ✨
string
hashes
lists
sets
sorted sets → redis 제공
bitmap
hyperloglog
geospatial index (지리공간 인덱스)
스트림 (streams)
in-memory ✨
disk가 아닌 memory(RAM)에 저장한다 → 휘발성 (서버에 장애가 발생하면 유실됨)
속도 때문! disk I/O 작업이 발생하지 않아 빠른 속도가 큰 장점이다. (HDD 기준 수백배 빠름)
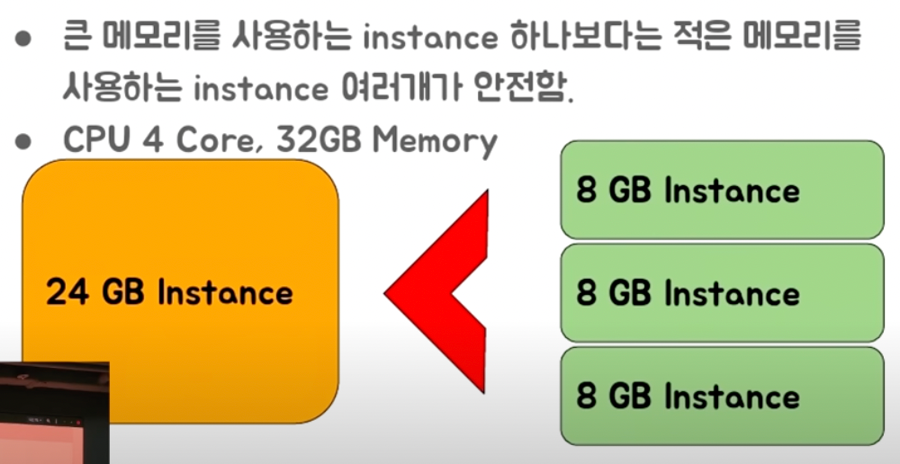
대신 RAM의 용량의 제한을 받음 → 메인 데이터베이스로 사용하기엔 무리, 메모리 관리가 중요
single thread ✨
한번에 하나의 명령만 처리 가능
중간에 처리 시간이 긴~ 명령어가 들어오면 대기해야함
get, set 명령어의 경우 초당 10만개 이상 처리 가능할 만큼 빠르다!
O(N)관련 명령어를 지양하자KEYS→ SCAN 명령어로 끊어서 key값 조회FLUSHALL,FLUSHDBDeleteCollectionsGet All Collections→ collection 일부만 가져오기, collection을 한번에 저장하지 말고 나눠서 저장
Redis를 언제, 어떻게 사용해야 할까
💡 캐시 데이터베이스 서버
기존의 데이터베이스는 데이터를 물리 디스크에 직접 쓰기 때문에, 서버가 다운되더라도 데이터가 손실되지 않는다.
하지만 서비스의 사용자가 늘어나서 데이터베이스가 과부하가 될 수 있다면
캐시 서버를 도입할 수 있는데, 이 캐시 서버로 이용할 수 있는 것이 Redis같은 요청이 여러 번 들어오는 경우 매번 데이터베이스를 거치는 것이 아니라 캐시 서버에 값을 저장해두고 꺼내올 수 있게 함 → 데이터베이스 부하를 줄이고 속도를 유지 가능
속도가 장점! ✨
고속 읽기와 쓰기에 최적화 된 경우가 많음
사용자의 프로필 정보
웹 서버 클러스터를 위한 세션 정보
장바구니 정보 등,,
Remote Data Store
A, B, C 서버에서 데이터를 공유하고 싶을 때
전역 변수로 선언하는 것보다, redis 자체가 atomic을 보장해준다.(싱글 스레드)
인증 토큰 저장 (string, hash)
ranking 관리 (sorted set)
유저 API limit
Redis를 효율적으로 사용하기
Redis Replication
💡 master-slave 형식의 데이터 이중화 구조
Redis 서버는 보통 단독으로 사용되지 않음 → Master의 데이터를 Replica로 복제 (비동기적)
Replication 설정 과정
Secondary에
replicaof****or ****slaveof명령 전달replicaof <hostname> <port>
Primary는 현재 메모리 상태를 저장하기 위해
forkfork한 프로세서는 현재 메모리 정보를 disk에 dump
해당 정보를 secondary에 전달
fork 이후의 데이터를 secondary에 계속 전달
Replication 주의점
replication 과정에서 순간적으로 fork가 발생하므로 메모리 부족이 발생할 수 있음
많은 대수의 redis 서버가 replica를 두고있을때,,
네트워크 이슈나 사람의 잘못된 조작으로 동시에 replication이 재시도된다면 문제가 발생
Q. 같은 네트워크안에서 30GB를 쓰는 Redis Master 100대가
replication을 동시에 재시작하면 어떻게 될까?
Redis Cluster
💡 데이터를 여러 개의 Master(Redis Node)에 나누어 저장 == 분산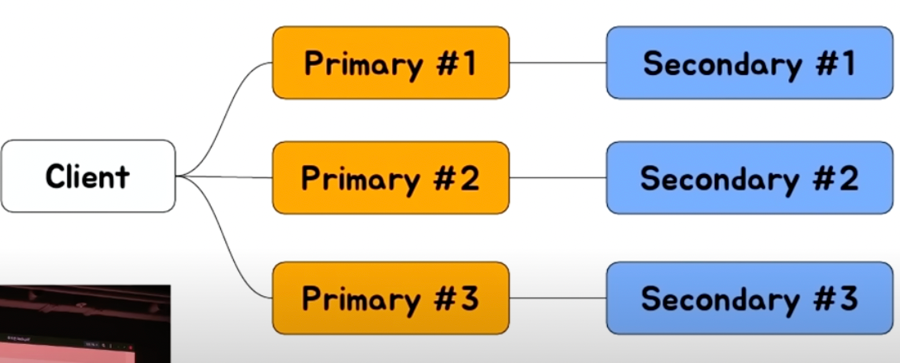
장점
자체적인 primary-secondary failover
master 서버가 죽으면 해당 slave 서버가 master가 됨
죽었던 master 서버가 올라오면, 새 master가 된 slave는 계속 master, 올라온 (전) master는 slave가 됨
일부 서버가 죽거나 장애가 발생해도 작업을 계속 할 수 있음
단점
메모리 사용량이 많음
migration 자체는 관리자가 시점을 결정해야 함 (Primary 1의 데이터를 Primary 2로 보내겠다,,)
Redis Sharding
💡 분할 된 여러 Redis Server(master)로 데이터를 분할
분산 서버 환경에서,,
데이터를 어떻게 나눌 것인가
데이터를 어떻게 찾을 것인가
하나의 데이터를 모든 서버에서 찾아야 한다면,, 끔찍
샤딩 전략
RANGE서버의 range을 정의하고 해당 range에 속하면 그 서버에 데이터를 저장
key 500을 어디에 저장할까?
1-1000 / 1001-2000 / 2001-3000
만약 게임에서 유저를 저장 → 유저의 가입일 수로 range를 나눈다면,,
신규 유저 이벤트를 한 기간 동안 유저수가 폭등할 것
Modular✨N % K로 서버의 데이터를 결정
key 값에 대해 해시함수를 적용한 결과를 redis master의 개수만큼 modular 연산하여 서버를 지정 (hash partitioning)
Range를 정의하는 것보다 데이터를 균등하게 분배 할 가능성이 높다.
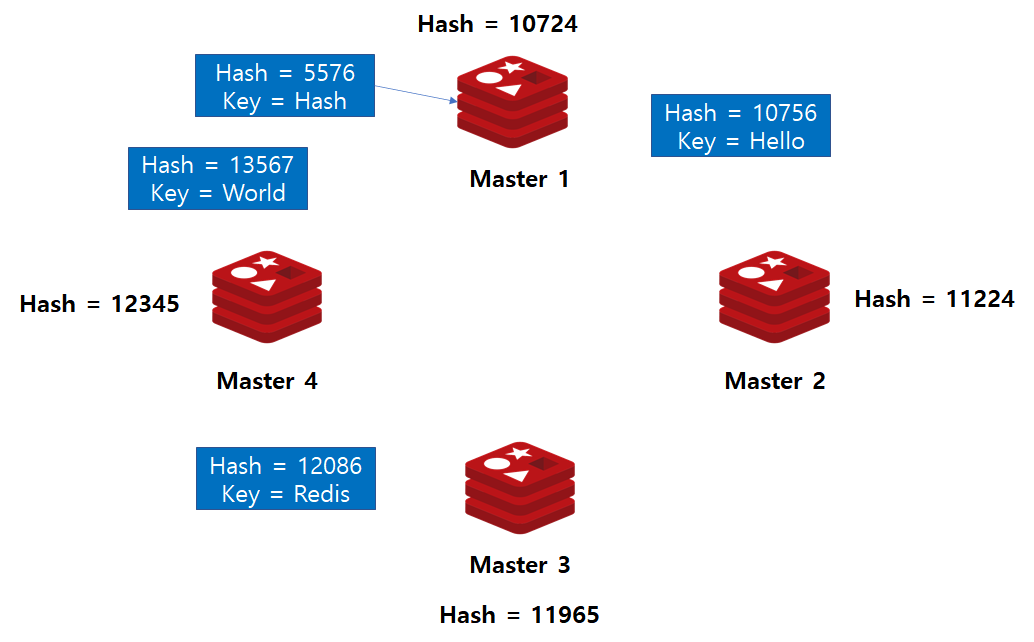
Consistency Hashing
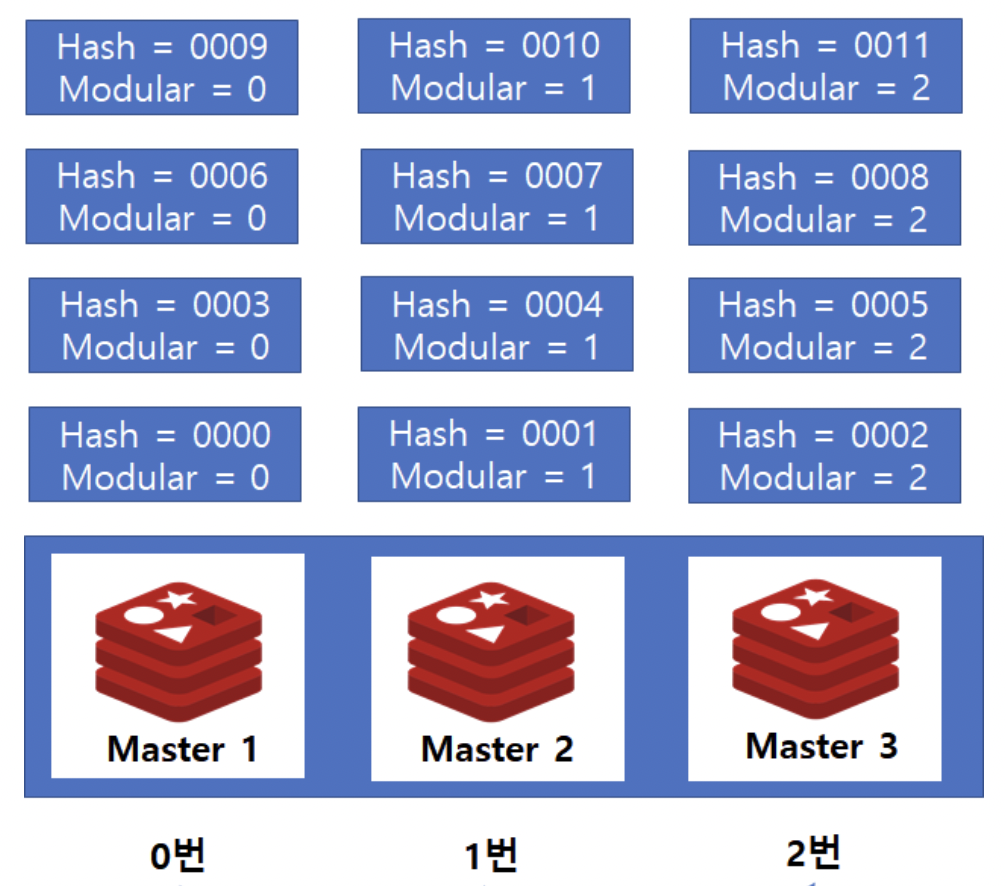
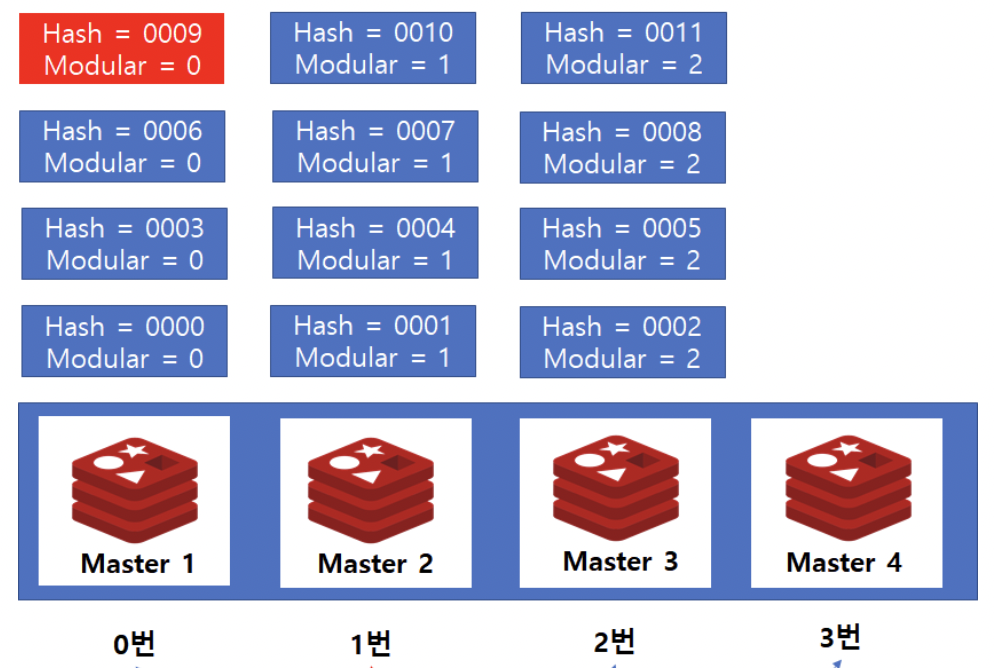
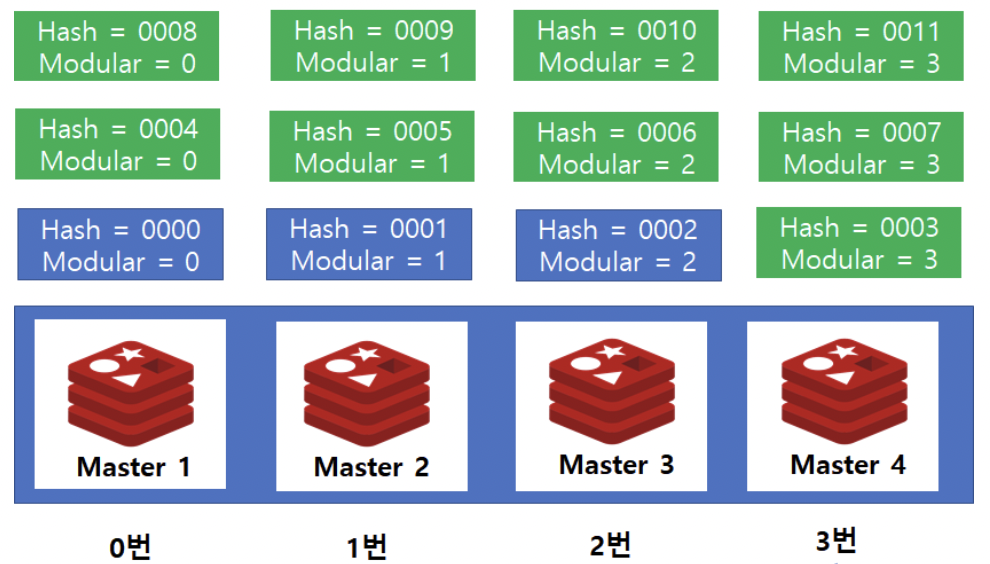
hash = 9인 데이터를 찾기 위해서는 9 % 3 → Master 1 서버에서 찾으면 됨
만약 master4가 추가된다면?
9 % 4 → Master2 라는 엉뚱한 서버에 질의하게 됨
그래서 서버가 추가되면 데이터
Rebalancing작업이 필요함!modular 전략으로 인한 rebalancing 작업은 굉장히 많은 비용이 발생
💡 rebalancing 대상이 되는 데이터 양이 적으면 되는거 아닐까?
Consistency Hashing 기법은 데이터 뿐 아니라 master에도 hash 함수 적용
master 서버 해시 값 기준으로 range를 나누어 데이터를 저장
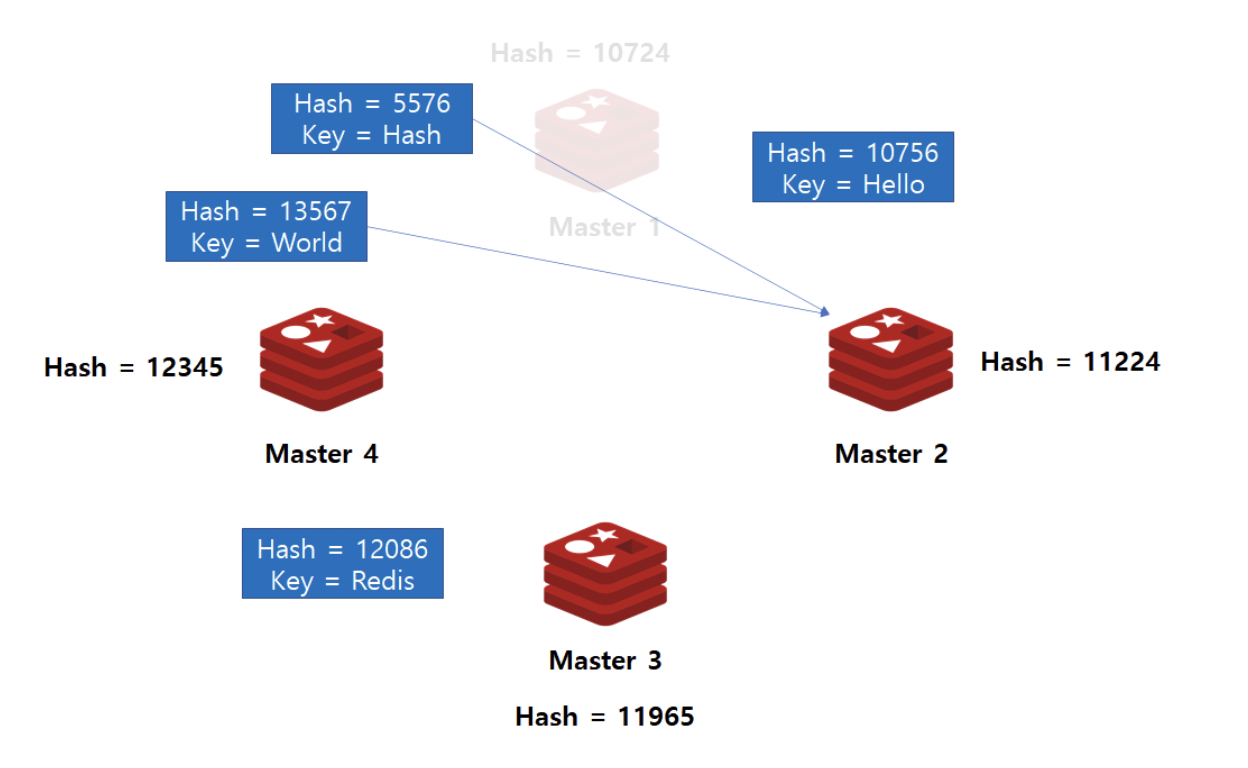
오른쪽 처럼 master1 서버(노드)가 삭제 → master1의 데이터를 rebalancing 해야함
master1 → master2로 데이터 전부 이동? (인접한 노드로 이동한다,,?)
가상 노드
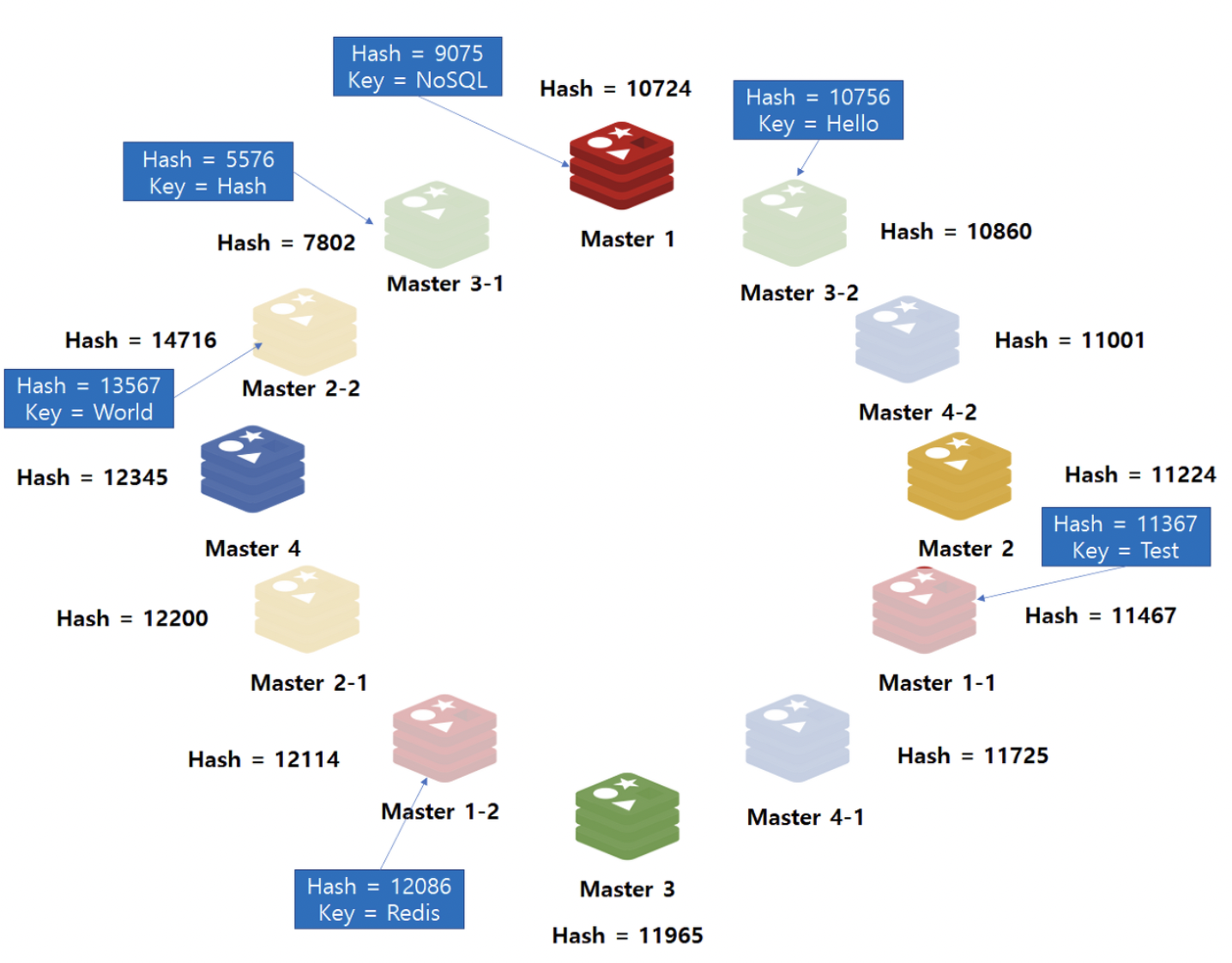
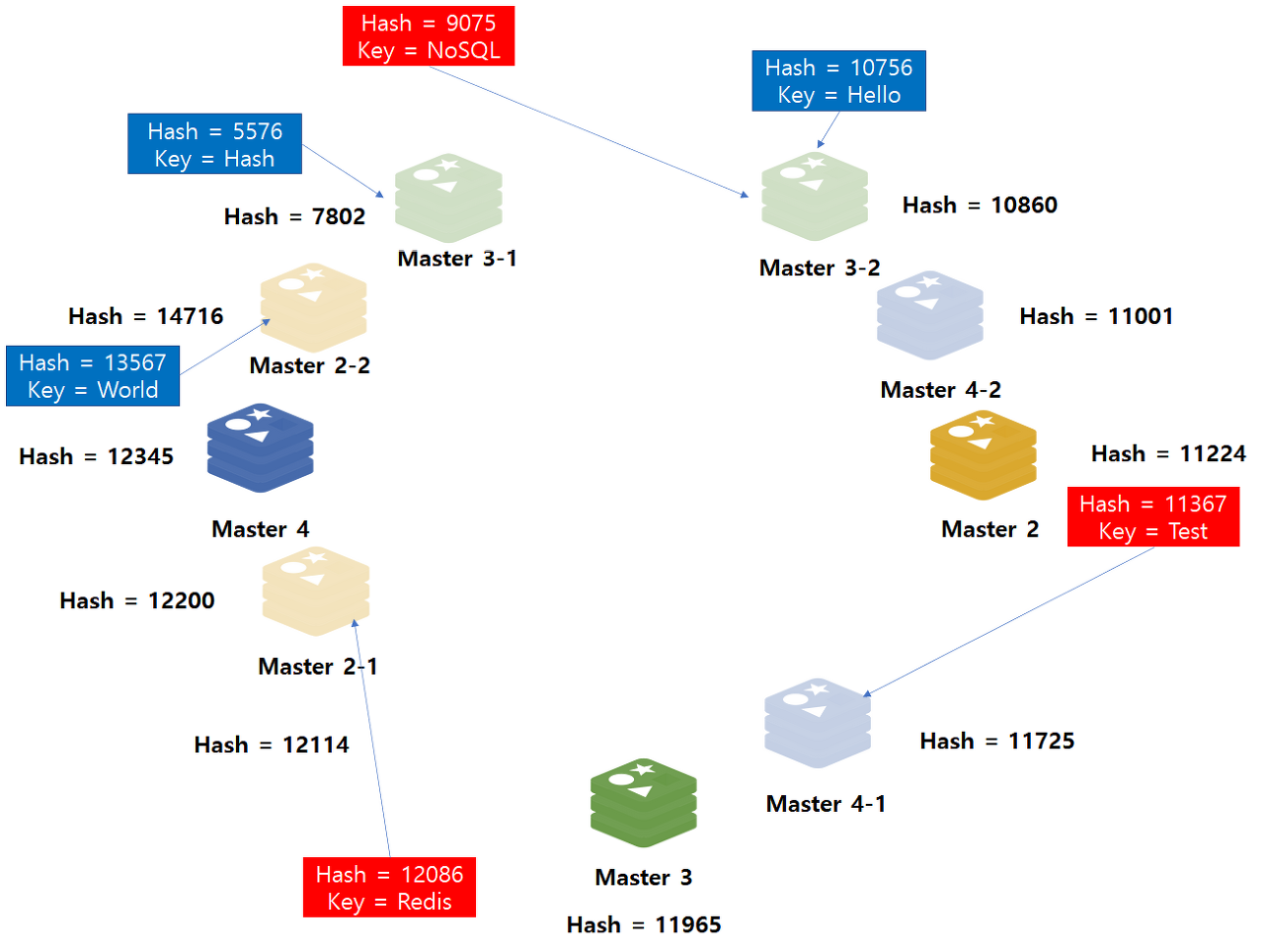
여러 개의 가상 노드를 배치하면 노드와 데이터 사이의 해시 값 범위가 좁아지게 된다 !
노드 사이의 범위 ⬆ rebalancing할 데이터 양 ⬆
해시 파티셔닝을 사용해서 데이터를 균등하게 분포 & 데이터 rebalancing 비용을 최소화하기 위해 consistent hashing 알고리즘 이용 → 가상 노드를 촘촘하고 균일한 간격으로 배치하기 위한 hash 알고리즘을 적용해야 함
Redis Sentinel / Topology / Failover
💡 장애 복구 시스템
Last updated